3.9. Стандартизация теста
Одним из важных отличий психометрических тестов является то, что они стандартизированы, а это позволяет сравнить показатели, полученные одним испытуемым, с таковыми в генеральной совокупности или соответствующих группах.
Тем самым достигается адекватная интерпретация показателя отдельного испытуемого. Таким образом, стандартизация теста наиболее важна в тех случаях, когда осуществляется сравнение показателей обследуемых. При этом вводится понятие нормы, или нормативных показателей. Для получения стандартных норм нужно тщательно отобрать большее количество испытуемых в соответствии с ясно обозначенным критерием. При формировании выборки стандартизации следует учитывать ее объем и репрезентативность. В руководствах по тестам чаще всего указывается на то, что для простого уменьшения стандартной погрешности достаточной будет выборка из 500 испытуемых. Однако репрезентативность выборки не зависит от ее объема. Например, для того чтобы получить нормативные показатели для всей популяции детей, обучающихся в начальной школе, потребуется выборка объемом более 10 тыс., тогда как выборка из такой ограниченной популяции, как шеф-пилоты авиакомпаний, не может быть столь значительной. Репрезентативность выборки, таким образом, параметр более важный, нежели ее объем. В некоторых случаях приходится формировать несколько групп стандартизации или стратифицировать группу стандартизации относительно таких параметров, как возраст, пол, социальный статус. Устанавливать нормы не всегда обязательно. При использовании психологических тестов в научном исследовании нормы не столь важны и достаточно «сырых» показателей теста.
Нормы для каждой группы должны быть представлены в средних величинах и показателе стандартного отклонения. Расчет средней величины элементарен и хорошо известен, а стандартное отклонение определяется с помощью формулы, имеющей вид:
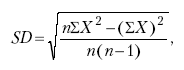
где SD – стандартное отклонение; X – результат всего опросника всех испытуемых; п – количество испытуемых; ? – сумма.
Сегодня на практике все больше используется такой тип производной оценки, как стандартные показатели, удовлетворяющий большинству требований, предъявляемых к психологическому измерению. Такие показатели выражают отличие индивидуального результата испытуемого от среднего в единицах стандартного отклонения соответствующего распределения. Стандартные показатели получают двумя путями: линейным и нелинейным преобразованием первичных («сырых») оценок. В случае линейного преобразования сохраняются все свойства исходного распределения «сырых» оценок, и такие показатели называются стандартными или z-показателями. Для вычисления z-показателя находят разность между первичной оценкой и средним для нормативной группы и делят ее на стандартное отклонение нормативной группы. Формула имеет вид:
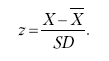
Здесь необходимо сказать о том, что основной причиной преобразования первичных оценок в некоторую производную шкалу является желание получить показатели, которые сопоставимы между собой вне зависимости от того, по какому тесту они получены. Линейное преобразование позволяет получить показатели сопоставимые лишь в том случае, когда распределения «сырых» оценок, по которым они рассчитываются, имеют примерно одинаковую форму. Для того чтобы сопоставлять показатели, полученные на основе распределений разной формы, прибегают к нелинейному преобразованию, или к нормализованным стандартным показателям. Процедура нелинейного преобразования достаточно проста и описана в многочисленных руководствах по математической статистике. Такие показатели обычно рассчитывают с помощью таблиц. В этих таблицах приводится процент случаев, приходящихся на участки, которые отстоят от среднего нормальной кривой на некоторое число единиц стандартного отклонения. Сначала определяют процент лиц, чьи показатели превышают каждую «сырую» оценку, а затем по этому проценту в таблице отыскивают соответствующее значение нормализованного стандартного показателя. Эти показатели, как и линейно преобразованные, будут иметь среднее (X), равное 0, и стандартное отклонение (SD), равное 1. Нулевое значение показывает, что испытуемый попадает в точку, соответствующую среднему нормальной кривой, превосходя 50 % группы. В случае если показатель равен -1, испытуемый превосходит примерно 16 % группы, а если +1 – превосходит 84 % группы. Нормализованным стандартным показателям можно придать любую удобную форму, например, умножив его на 10 и прибавив произведение к 50, получаем так называемый «Т-показатель» и в этом случае Т, равное 50, соответствует среднему, равному 60 – превышает среднее на одно стандартное отклонение и т. д. С другими, не менее популярными нелинейными преобразованиями «сырых» показателей теста можно ознакомиться в соответствующей литературе[69].
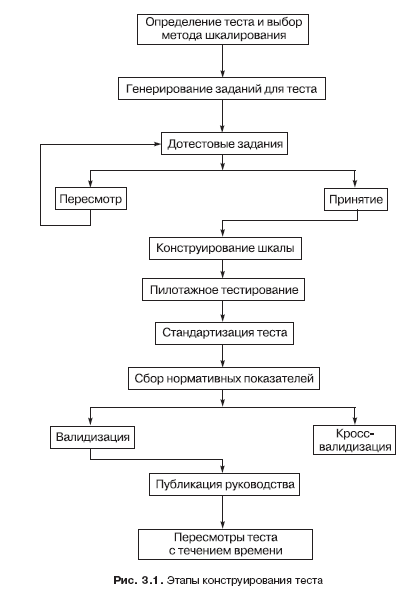
Созданием стандартизованного теста и его публикацией обычно завершается работа психолога, однако следует помнить и о том, что с течением времени необходим пересмотр (ревизия) теста. Достаточно вспомнить о тестах интеллекта (см. гл. 4), нормы по которым устаревают через каждые 5 лет, и можно предположить, что процесс их старения будет ускоряться. Для наглядности этапы конструирования теста представлены на рис. 3.1.
Пример из практики: определение надежности опросника 16PF Кеттелла. Личностный опросник Раймонда Кеттелла 16 PF (16 личностных факторов) относится к наиболее распространенным психодиагностическим инструментам и не нуждается в специальном представлении. Уже без малого 50 лет психологи всего мира используют его для решения разнообразных прикладных и научных задач. Однако как в бывшем СССР, так и ныне во вновь образованных странах этот опросник, несмотря на достаточно большую популярность, используется непрофессионально, с нарушением всех норм и правил, предъявляемых к психологическим тестам.
Кроме различных переводов опросника, которые существенно отличаются один от другого, в русскоязычной литературе часто встречаются и различные «ключи» к его факторам. Опубликованные в многочисленных сборниках и брошюрах варианты опросника не защищены (!) от ошибок и произвольного вмешательства в его текст. Если добавить к этому отсутствие нормативных данных, а также то, что не проводилась проверка гомогенности шкал опросника на отечественных выборках, то непонятно, какого рода результаты получали его многочисленные пользователи, какими диагностическими заключениями они оперировали. За последние пятнадцать лет у нас появились только три (!) работы, в которых ставилась задача проверки факторной структуры 16PF на национальных выборках: это статьи В. М. Русалова и О. В. Гусевой (1990), Ю. М. Забродина, В. И. Похилько и А. Г. Шмелева (1987), наконец, украинского психолога А. Г. Виноградова (1997). Читателю нетрудно сравнить это количество публикаций с тем множеством работ, в которых опросник использовался для получения «диагностически значимых результатов». Сказанное позволяет сделать вывод о том, что с помощью опросника 16PF измеряется нечто, имеющее неясное отношение к факторам личности, выделенным и описанным Кеттеллом.
Занимаясь работой по психометрической адаптации личностных опросников[70], мы не могли обойти вниманием и столь широко распространенный, как 16PF. За основу была взята форма «А» опросника 16PF. Были обследованы 227 человек (135 женщин и 92 мужчины) в возрасте от 16 до 51 года. Средний возраст исследуемых составлял 28 лет. Это были люди, которые проходили отбор на различные должности в коммерческие организации Киева, все они имели высшее или среднее специальное образование (бухгалтеры, коммерческие директора, менеджеры разного уровня).
Как известно, точность измерения с помощью психодиагностического инструмента определяется его надежностью. С целью выяснить, насколько точен прогноз, даваемый психологом на основании результатов 16PF, данные, первоначально полученные нами, были оценены по авторским ключам на внутреннюю согласованность с помощью коэффициента Кронбаха, вычисляемого по следующей формуле:
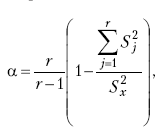
где ? – коэффициент Кронбаха; r – количество заданий теста; S2j– дисперсия по j-му пункту теста; S2X – дисперсия суммарных баллов по всему тесту.
В табл. 3.6 содержатся данные о внутренней согласованности факторов личности, полученные по авторским «ключам» (приведено буквенное обозначение фактора). Как видно из таблицы, значение коэффициента Кронбаха неудовлетворительно для большинства факторов. А фактор N вообще измеряет нечто, не имеющее никакого отношения к проницательности, расчетливости и наивности (если употреблять обыденное название этого фактора). Лишь некоторые из факторов, например фактор F(сургенция-десургенция) и фактор H пармия – тректия (смелость – робость), надежно измеряют то, что должны измерять. Таким образом, в результате проверки надежности-согласованности оригинальных ключей было показано, что ряд шкал опросника негомогенны. Можно предположить, что это следствия искажения смысла заданий при переводе на русский язык и/или существования известных культурных различий.
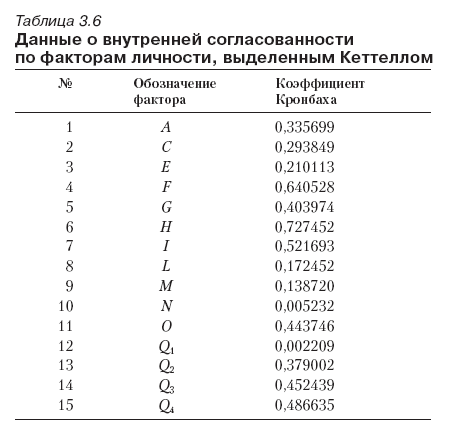
Для того чтобы выявить, что же именно стоит за данными, получаемыми с помощью 16PF, мы использовали факторный анализ. Факторы извлекались методом главных компонент; оценка общностей производилась после выделения факторов. Решение о количестве факторов принималось на основании анализа диаграммы собственных значений – scree-plot (рис. 3.2). На так называемом «графике осыпи» (автором которого является Кеттелл) находилась точка перегиба, правее которой, как показали модельные эксперименты автора опросника, обычно расположены так называемые «шумящие» факторы. Этот критерий позволяет выделить гораздо меньшее число факторов, чем применяемый большинством пользователей статистических пакетов метод Кайзера, базирующийся на величине собственного значения фактора. Вращение факторов производилось методом VARIMAX с нормализацией по Кайзеру. Коэффициенты факторных баллов были вычислены методом регрессии. Статистическая обработка производилась с помощью программы SPSS для Windows (версия 5.0). В качестве значимых рассматривались нагрузки заданий, которые по абсолютной величине превосходили 0,3. Данная граница была принята по следующим соображениям: поскольку нагрузка представляет собой коэффициент корреляции задания и фактора, при данном его объеме эта величина является значимой и позволяет объяснить до 10 % вариации задания. Как показывает опыт, установление более высокой границы приводит к резкому падению согласованности шкалы, особенно при кросс-валидизации. При этом заметим, что небольшое количество наших испытуемых, конечно, не репрезентирует генеральную совокупность. Кроме того, нами не проводилось исследование стойкости факторного решения, полученного в исследовании (кросс-валидизация). Наконец, задания по фактору В, а также задания 1, 2 и 187 были исключены из анализа.
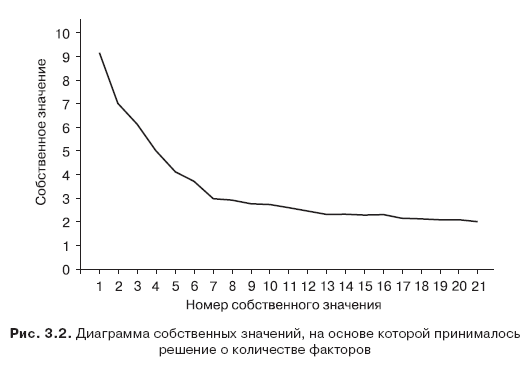
Обычно на таком графике кривая имеет две точки изгиба. Для интерпретации оставляют те факторы, которые размещены перед вторым изгибом кривой. Получается, что в нашем случае следует оставить 7 факторов. Интересно, что приблизительно такое же количество факторов обнаруживается в большинстве исследований структуры личностной лексики в разных языках и совокупностей заданий личностных опросников. Выделенные факторы были интерпретированы следующим образом.
1. Тревожность – эмоциональная стабильность.
2. Энергичность, активность – пассивность.
3. Настойчивость, уверенность в себе – покорность, подверженность влиянию.
4. Сила Сверх-Я – слабость Сверх-Я (данный фактор соответствует фактору G Кеттелла).
5. Обособленность – зависимость от группы (этот фактор соответствует фактору Q2 Кеттелла).
6. Рациональность, практичность – мечтательность.
7. Импульсивность – сдержанность, самоконтроль.
Интересным представляется тот факт, что лишь три отмеченных фактора соответствуют тем, которые выделены Кеттелом. Это, на наш взгляд, свидетельствует о том, что данные факторы (G, Qз и Q2) настолько устойчивые характерологические конструкты, что имеет сходство в англоязычной и русскоязычной культурах. Также заслуживает внимание тот факт, что большинство факторов соответствуют факторам, полученным в других работах (Виноградов, 1997). Это еще раз подтверждает надежность полученных результатов.
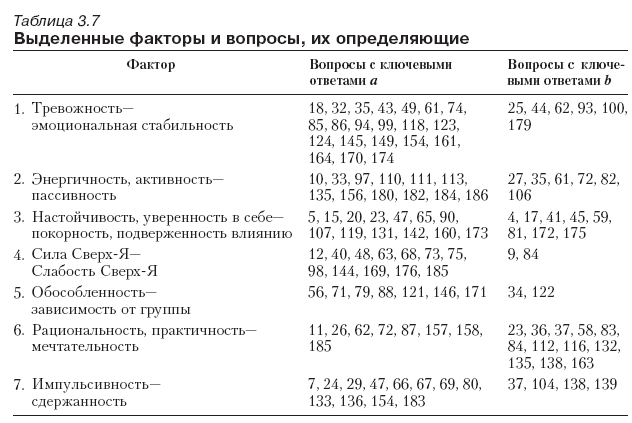
Нагрузки заданий опросника по семи факторам приведены в табл. 3.7 (включены нагрузки, абсолютное значение которых не менее 0,3).
Вопросы, «работающие» на выделенные факторы, были подвергнуты статистической обработке с последующим анализом полученных показателей внутренней согласованности. Результаты представлены в табл. 3.8.

Нетрудно убедиться, что значения коэффициента надежности-согласованности Кронбаха достаточно велики для выделенных факторов, а это свидетельствует об однородности построенных шкал. Поскольку не существует формальных способов проверки гипотезы о равенстве нулю коэффициента Кронбаха, в своей работе мы использовали его лишь в качестве дескриптивной меры согласованности заданий исходных и полученных с помощью факторного анализа шкал. Напомним, что для шкал опросников наиболее характерны значения коэффициента Кронбаха в диапазоне 0,6–0,8.
На завершающем этапе исследования нами были рассчитаны среднее и стандартное отклонения для новых и оригинальных ключей (табл. 3.9, 3.10)[71].

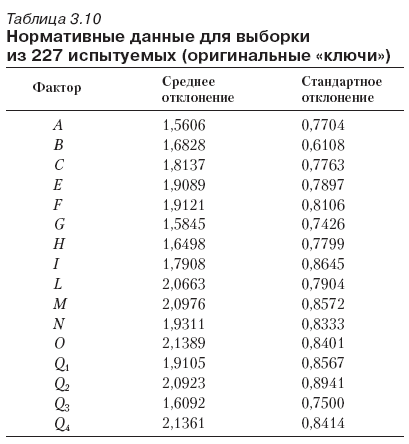
Результаты проведенного исследования позволили ответить на вопрос о том, насколько мы точны в измерении факторов, постулированных Кеттеллом. Предварительные нормативные данные могут служить ориентиром для заключений об относительной степени выраженности у испытуемого некоторых личностных черт. Памятуя об ограниченности выборки, отметим, что новые «ключи» и нормы следует использовать с известной осторожностью.






