Предсказания на уровне населения
Некоторые вещи предсказать легко и делается это интуитивно. Примером может служить ситуация, когда болезнь публичного лица заставляет других людей искать в Интернете информацию об этой болезни или ее лечении8. Можно легко предсказать, что это случится, а поисковая активность просто отражает количественную сторону дела.
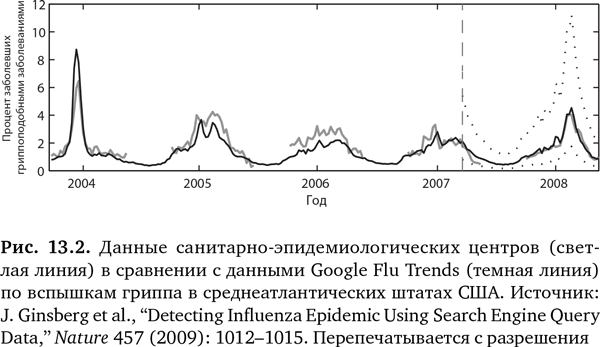
А что, если вы используете поисковики Google, чтобы с умом предсказывать болезнь, а не просто определить количество запросов? Это приводит нас к известной истории о гриппе, связанной с Google, – одному из самых цитируемых примеров предсказаний в здравоохранении9–16. Инициатива Google Flu Trends («Тенденции гриппа от Google») была запущена в 2008 г. и стала известна как «живой пример силы анализа больших данных». Сначала отслеживались 45 терминов, связанных с поиском информации по гриппу, и тенденции в миллиардах поисковых запросов в 29 странах10. Потом были выведены соответствия с помощью неуправляемых алгоритмов для предсказания начала эпидемии гриппа. Под неуправляемостью имеется в виду отсутствие заданной гипотезы – просто 50 млн поисковых терминов и алгоритмов делают свою работу. В широко цитируемых статьях в Nature12 и Public Library of Science (PLos) One11 авторы из Google (рис. 13.2) заявляли о своей способности использовать журналы поиска в Интернете для создания ежедневных оценок заражения гриппом, в отличие от обычных методов, которые предусматривают временной лаг от одной до двух недель. И далее, в 2011 г.: «Инициатива Google Flu Trends может обеспечить своевременные и точные оценки заболеваемости гриппом в США, в особенности во время пика эпидемии, даже в случае новой формы гриппа»11.
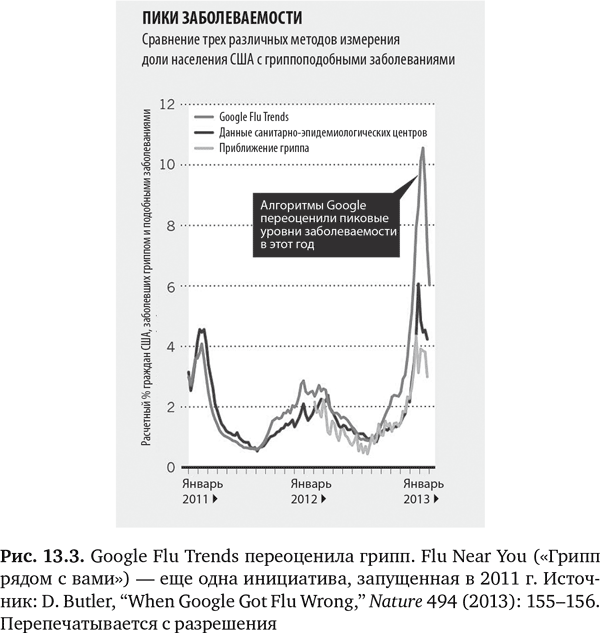
Но начало 2013 г. сопровождалось бурей противоречий: оказалось, что Google Flu Trends сильно переоценила вспышку гриппа (рис. 13.3). В дальнейшем группа из четырех очень уважаемых специалистов по обработке и анализу данных написала в Science, что Google Flu Trends систематически переоценивала распространение гриппа каждую неделю начиная с августа 2011 г. Далее эта группа критиковала «высокомерие больших данных», «распространенное представление, что большие данные скорее заменяют, чем дополняют традиционный сбор и анализ данных»17. Они ругали «динамику алгоритма» Google Flu Trends (GFT), указывая, что 45 терминов, используемых в поисковых запросах, не были документированы, ключевые элементы, как, например, основные условия поиска, не были представлены в публикациях, а изначальный алгоритм не подвергался постоянным настройкам и перепроверке. Более того, хотя алгоритм GFT был статичным, сам поисковик постоянно менялся, претерпев ни много ни мало 600 пересмотров за год, что в расчет не принималось. Многие другие авторы редакционных статей также высказались по данному вопросу13–15, 18, 19. Большинство из них обращали внимание на взаимосвязи вместо причинно-следственных связей и на критическое отсутствие контекста. Критиковали и методы выборки, так как краудсорсинг ограничивался теми, кто выполнял поиск в Google. Кроме того, наблюдалась серьезная аналитическая проблема: GFT проводила столько многочисленных сравнений данных, что была вероятность получения случайных результатов. Все это можно рассматривать как обычные ловушки, когда мы пытаемся понять мир через данные13. Как написали Кренчел и Мадсбьерг в Wired: «Высокомерие больших данных состоит не в том, что мы слишком уверены в наборе алгоритмов и методов, которых еще в общем-то нет. Скорее проблема в слепой вере в то, что достаточно, сидя за компьютером, перемалывать цифры, чтобы понять окружающий нас мир во всей его полноте»19. Нам нужны ответы, а не просто данные. Тим Харфорд выразился в Financial Times без обиняков: «Большие данные уже здесь, но великих озарений нет»18.
Некоторые принялись защищать GFT, указывая, что данные были всего лишь дополнением к санитарно-эпидемиологическим центрам, а Google никогда не заявляла, что обладает магическим инструментом. Наиболее взвешенную точку зрения выразили Гари Маркус и Эрнест Дэвис в своей статье «Восемь (нет, девять!) проблем с большими данными» (Eight (No, Nine!) Problems With Big Data)20. Я уже обращался ко многим их выводам, но мнение Маркуса и Дэвиса насчет беззастенчивой рекламы больших данных и относительно того, что? большие данные могут (и чего не могут), заслуживает особого упоминания: «Большие данные повсюду. Кажется, что все их собирают, анализируют, делают на этом деньги и прославляют их силу или боятся их… Большие данные никуда не денутся, как и должно быть. Но давайте будем реалистами: это важный ресурс для всех, кто анализирует данные, а не серебряная пуля»20.
Несмотря на проблемы с GFT, подобные шаги никуда не ведут. Альтернативный и более поздний подход – это предсказание вспышки заболеваемости с использованием меньшей базы людей, которые активно поддерживали связь в Twitter, – так называемых «центральных узлов», когда люди по сути выступают в качестве датчиков21а. Это позволило обнаружить вспышки вирусных заболеваний на семь дней быстрее, чем когда рассматривалось население в целом. Точно так же алгоритм HealthMap, который проводит поиск в десятках тысяч социальных сетей и новостных СМИ, смог предсказать вспышку лихорадки Эбола в 2014 г. в Западной Африке на девять дней раньше Всемирной организации здравоохранения21b. Я углубился в историю, связанную с Google и гриппом и вспышками заразных болезней, потому что они отображают ранние этапы пути, по которому мы идем, и показывают, как мы можем заплутать, используя большие массивы данных для предсказаний в медицине. Но знать, как мы сбились в пути, важно, если мы собираемся по нему двигаться.






