Человек и Интернет медицинских вещей
Теперь мы готовы говорить о медицине и ее возросшей, благодаря нашим цифровым машинам и инфраструктуре, интеллектуальной мощи. В настоящее время количество данных, ежегодное производимое в мире в расчете на одного человека, составляет около одного терабайта, или пяти зеттабайтов, данных в год (или 40 секстильонов). Но вспомните из главы 5, когда мы говорили о человеческой ГИС, что только омики одного человека добавят по крайней мере еще пять терабайтов, а мы еще не достигли даже потокового поступления данных с биодатчиков в режиме реального времени, которые быстро заполонят объем генерируемых сейчас данных. И тем не менее едва ли достаточно добавить другие компоненты ГИС, в частности поток данных в пикселях медицинских снимков и предстоящий шквал информации из Интернета медицинских вещей, чтобы все преобразилось.
Но это, безусловно, не просто история исследования с участием одного человека (N = 1). Как было показано в главе 11, хотя иметь много данных о вас было бы полезно, для того, чтобы сделать данные максимально информативными, нужно сравнить их со всеми данными от каждого человека на планете (рис. 13.4). До всех людей мы никогда не доберемся, тем не менее чем их больше, тем лучше, и компании типа Facebook показывают, что можно сделать.
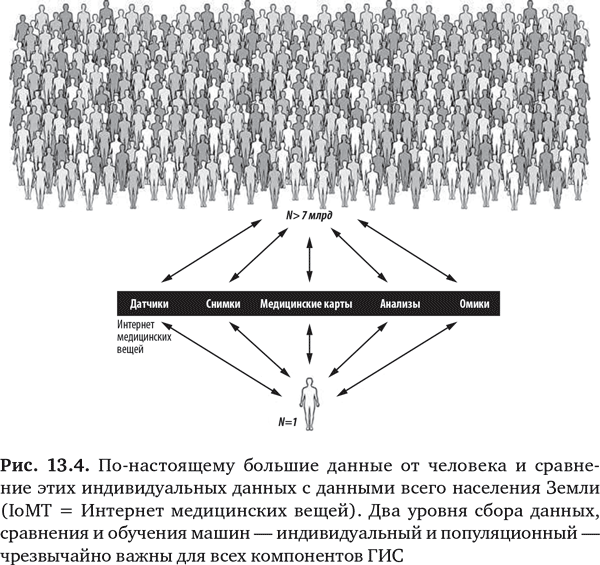
Главное, что обучение машин, подобных стоящим за IBM Watson и другими системами, позволяет нам идти вширь (N = 7 млрд) и вглубь (N = 1) не просто в поисках знаний, но и в поисках предсказаний и понимания. В отношении каждого человека нам нужно знать пусковые механизмы и сложные взаимосвязи на многочисленных уровнях – геномном, биологическом, физиологическом, средовом, – которые отвечают за предрасположенность к заболеванию или состоянию. Цель – не просто оценить риск в течение жизни человека, а в определенное время или момент. Многое мы узнаем и в результате углубленного исследования максимально возможного количества людей на предмет сигналов, обогащающих наше понимание того, что требуется для проявления болезни или для ее предотвращения. Только сейчас мы можем собрать такие паноромные данные по каждому отдельному человеку и в группах населения, и, обладая способностью управлять и обрабатывать огромные наборы данных, мы оказываемся в завидном положении предсказателей болезни. И, может быть, после того, как мы научимся все это делать хорошо, нам удастся даже предотвращать болезни у некоторых людей.






